| |
dicembre |
Paolo Canettieri, Vittorio Loreto, Marta Rovetta, Giovanna SantiniECDOTICS AND INFORMATION THEORY |
Data d'immissione: Dicembre 2005 |
1. Introduction
Behind the philological activity lies a primary cognitive requirement of man which consists in specifying the sense or literal meaning of what has been said by another man or group of men, generally of greater authority. In this sense, the mental outline controlling such an activity can therefore be synthesized as: /A has not said x, A has said y/. This requirement derives, essentially, from the loss of information inherent in any type of data transmission. In the pre-technological age, information was transmitted in an exclusively oral form and useful mental techniques have been necessary to reconstruct the original dictation, a practice certainly supported by the hierarchical structure of society.
Before the invention of printing, texts was copied by hand and variants were typically introduced by the scribe. Textual criticism examines the extant copies to sort through the variants and to establish a ‘critical text’ as close as possible to the original. The difficulty is that it is not always apparent which variant is original and which one is innovative.
There are two different approaches to textual criticism: copy text editing and ecdotics. In the former, the textual critic selects a base text from a manuscript and makes emendations in places where it appears wrong. In the latter, ecdotic critic examines the variants in order to find patterns of error, requiring to reconstruct the history of the text. According to the principle that “a community of error implies a unity of origin”, the critic determines the relations among the extant manuscripts, so as to place them in a family tree (stemma codicum).
Here we proposed an integrated method for "stemma" reconstruction which combines the traditional ecdotics approach with an information theory oriented methodology. In the information theory oriented approach the key element is the definition of a notion of "distance" between pairs of manuscripts and its computation is based on data compression techniques. All the pair-wise distances among all the manuscripts in the corpus form the so-called distance matrix which is used to construct a phylogenetic-like tree by minimizing the net disagreement between the matrix pairwise distances and the distances measured on the tree. This phylogenetic-like tree is compared with the others constructed with the traditional ecdotics method and a consensus tree is obtained.
For a short and oversimplified summary of our information-theory oriented approach we refer to Canettieri et al., 2005).
2. Phylogenetic trees and stems
As is well known, tree-like structures are designed to represent phylogenetic relations among genes or organisms and have been used several times in humanistic studies to classify the genealogic relations among the cultures of different populations (Shevoroshkin, 1989), linguistic families (Greenberg 1957; Stevick 1963; Maher 1966; Bender, 1976; Picardi 1977; Koerner, 1981 e 1983; Flight 1988; Bateman et al., 1990; Hoenigswald 1990; Shevoroshkin and Woodford, 1991; Cavalli Sforza et al., 1994; Gray and Jordan, 2000; Searls, 2003) and manuscript witnesses of a text (Platnick and Cameron, 1977; Timpanaro 1985; Antonelli, 1985; Cameron, 1987; O’Hara, 1996; Montanari 2003). As regards textual criticism, the software developed for use in biology has been first applied by the Canterbury Tales Project to determine the relationships among the 84 surviving manuscripts and four early printed editions of the Canterbury Tales (O’Hara and Robinson, 1993; Barbrook et al., 1998; Robinson et al., 2003; Spencer et al., 2003). The texts of different manuscripts are entered into a computer, which records all the differences among them. The manuscripts are then grouped together according to their shared characteristics.
The trees of the biologists are generally formed on the basis of mutations, which are therefore very similar to the variants in ecdotics (Spencer and Howe, 2001 and 2002; Spencer et al., 2004). They present properties which are similar to those found in the evolution of texts, as they admit lost elements. Despite the identification of typical analogies existing among the various trees, scholars in the single disciplines have not adopted a uniform terminology. We feel that the terminology realized by the mathematicians who have studied the theory of the graphs is the most appropriate and precise (Bollobás, 1998; Douglas, 2001). ‘Graphs’ are mathematical structures formed by ‘nodes’ (single elements identified by a label) and edges or links connecting pairs of nodes. The trees are a particular family of graphs which can be defined as a connected and acyclic oriented graph. In a tree there exists a privileged node called root. The nodes connected to the root are called children and the root is their ancestor. In the trees the children are not interconnected by any edge and there is only one edge linking them to the root. However, various edges can be traced for each child-node of the root so that it may be connected to new nodes that we call children of this node and which, in turn, will be called ancestors. The terminology and the initial ties are extended to the new descendants and to the descendants’ descendants, and so on recursively. Therefore each node has only one ancestor but in principle many children. The nodes without children are called leaves.
Any node A is defined as ancestor of a node B if there exists a node C which is the child of A and ancestor of B. This is a recursive definition. Since trees are mathematical structures defined recursively, it is often easier to express definitions, properties or algorithms on trees recursively. Broadly speaking, fathers are also called ancestors and the nodes of the same ancestor are defined as being dominated by that ancestor. All the nodes of a tree are dominated by the root.
In a graph the ‘path’ between two nodes is a sequence of edges that have to be crossed in order to reach one of the two nodes starting from the other. The nodes that are linked at the root by means of a path constituted by the same number of edges forms a set which is called ‘level’ (the equivalent of ‘stemma level’ in ecdotics). Each level is univocally identified by this number and is separated from the other levels: the greater the number defining a level, the lower is the level itself; the smaller the number, the higher is this level. The lowest level is always formed by leaf-nodes, the highest level from the root.
In genetics trees can be rooted or unrooted. The creation of these trees is based on different principles and the results depend on the method that has been chosen. The branching structure is called topology of the tree. The topology of trees with roots is also represented by setting in brackets the sequences that derive from the same node. For example the first tree of fig. 2 could also be represented grouping (A,B) and (C,D) first, and then these two new taxa (namely any taxonomic unit, e.g. species, populations, sequences, morphological features) as follows: ((A,B),(C,D)).
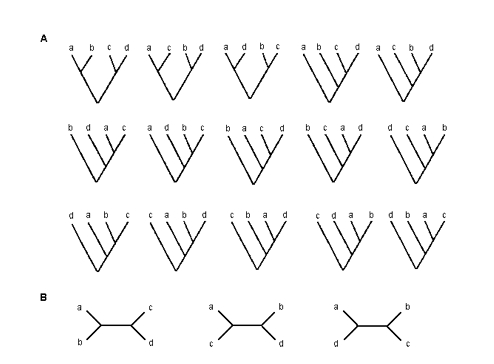
Figure 2. Possible rooted (A) and unrooted (B) trees with 4 elements.
Various trees are possible for a given number of species (m). For example if m = 4 there are 15 possible trees with roots and 3 without roots, as seen in fig. 2. The number of trees grows very rapidly with the number of taxonomic units (Edwards and Cavalli-Sforza, 1967): if m = 10 we will have more than 34 million possible trees, of which only one will be the true one. This means that it is practically impossible to assess the goodness of all the phylogenetic trees.
Phylogenetic trees generally regard species or populations and are constructed by comparing genes. One of the simplest methods, although it is not without errors, with particular regard to the topology of the tree, is the one based on the distance matrix.
A
matrix of (developmental) distances is constructed among the sequences, for
instance according to the mutations encountered. For example the
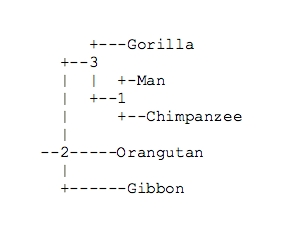
Fitch-Margoliash (Fitch, Margoliash 1967) method:
| 1) Man | 2) Chimpanzee | 3) Gorilla | 4) Orangutan | |
| 2) Chimpanzee | 0.095 | |||
| 3) Gorilla | 0.113 | 0.118 | ||
| 4) Orangutan | 0.183 | 0.201 | 0.195 | |
| 5) Gibbon | 0.212 | 0.225 | 0.225 | 0.222 |
We examine the table and look for the minor distance. The
two sequences (1,2) are grouped together and considered as a new sequence. The
length of the branches stretching from the bifurcation to nodes 1 and 2 is
assumed to be equal (thus = 0.095/2). The
table of the distances where 1 and 2 are grouped together is recalculated. Each
distance will be calculated as average of the distances from 1 and from 2.
| u) (1,2) | 3) Gorilla | 4) Orangutan | |
| 3) Gorilla | (0.113+0.118)/2 = 0.115 | ||
| 4) Orangutan | (0.183+0.201)/2 = 0.192 | 0.195 | |
| 5) Gibbon | (0.212+0.225)/2 = 0.218 | 0.225 | 0.222 |
At this point the minor distance is between (1,2) and 3. The
length of the branch leading to 3 will be half the distance between (1,2) and
3, while the length of the branch leading to the bifurcation between 1 and 2
will be such that - if added to the length of branch 1 - it will be the same as
the branch leading to 2. This procedure ensures that the distances in the
reconstructed tree are close to the ones that have been observed. (1,2) and 3
are grouped in ((1,2),3) and the matrix of the distances is recalculated:
| v) ( (1,2),3) | 4) Orangutan | |
| 4) Orangutan | (0.183+0.201+0.195)/3= 0.193 | |
| 5) Gibbon | (0.212+0.225+0.225)/3= 0.221 | 0.222 |
At this point the minor distance is between ((1,2),3) and 4.
((1,2),3) and 4 are grouped in (((1,2),3),4) and the distance matrix is
recalculated:
| z)( ( (1,2),3),4) | |
| 5) Gibbon | (0.212+0.225+0.225+0.222)/4 = 0.221 |
Finally, the following tree is obtained:
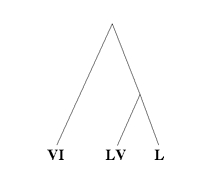
The application of methods like this to linguistics and textual criticism is now quite diffused, although it is still far from representing the real developmental processes appropriately. The methods are based on the comparison of sequences of characters and involves a grouping of those which appear closer to one another: it is obvious that in this way the trees are always dicotomic. It is instead clear that in both linguistics and ecdotics the vicinity of sequences does not necessarily imply a phylogenetic relation. This concept can be illustrated by two extreme cases: translations in different languages operated on the original or on the archetype would be placed in an extremely distant position one from the other. Otherwise, if we were to use the phylogenetic method to establish relations among interdependent languages, such as classical Latin (L), vulgar Latin (LV) and vulgar Italian (VI), the developmental process being L > LV > VI, L and LV would be sharing the same tree, while VI would be on another branch:
Likewise, if three copies of a text are in a dependence relation (A,B,C), but C presents a lacuna that A and B do not have, or has any singular alteration (interpolation, significant error, etc.), the tree produced by the phylogenetic analysis method will draw A and B closer with respect to C: ((A,B),C). We therefore come across a theoretical error which is similar to the one evidenced in the method of Dom Quentin and of his followers, who tried to automatize textual criticism (Quentin 1926; Froger, 1968).
In order to obtain scientifically remarkable results it is instead necessary to apply to the methods of phylogenetic analysis the most relevant achievements of the Lachmann method, based on evident errors and innovations (Maas 1957, Montanari 2003). This method can be summarized as follows: given two copies A and B of the same text, if: A contains an error (e1); B contains the same error; A contains an error e2 (different from e1); B does not contain e2; then: A derives from (<) B. This is an implication formula which can be expressed as follows:
[e1 ∈ A ∪ B, e2 ∈ A] ⇒ A < B.
On the other hand, if: A contains an error (e1); B contains the same error; B contains an error e2 (different from e1); A does not contain e2; then: B derives from A:
[e1 ∈ A ∪ B, e2 ∈ A] ⇒ B < A.
This formula detects the case of the so-called descripti (i.e. copies whose sources have been conserved), but it could be generalized. For example if: A contains an error (e1); B contains the same error; A contains an error e2 (different from e1); B does not contain e2; B contains e3 (different from e1 and from e2); A does not contain e3; then A and B are connected by the same node, which represents a lost copy. The formula can be expressed as follows:
[e1 ∈ A ∪ B, e2 ∈ A, e3 ∈ B] ⇒ (A,B).
In the case of three copies of a lost original, the formula will be:
[e1 ∈ A ∪ B ∪ C, e2 ∈ A, e3 ∈ B, e4 ∈ C ] ⇒ (A,B,C).
The variants (v) can also be used for creation of the tree. If we have witnesses A,B,C under the following condition (vs indicates that the variant implies the same textual site):
[e1 ∈ A ∪ B ∪ C, e2 ∈ B ∪ C, e3 ∈ A, e4 ∈ B, v1 ∈ A ∪ B vs v2 ∈ C],
we can consider v2 as separative variant of C with respect to B, in the same way as we consider e4 as separator of B with respect to C: ((B,C),A).
In case there are 4 copies available and the following conditions take place:
[e1 ∈ A ∪ B ∪ C ∪ D, e2 ∈ B ∪ C ∪ D, e3 ∈ A, e4 ∈ B, e5 ∈ C, e6 ∈ D, v1 ∈ A ∪ B vs v2∈ C ∪ D] ⇒ (((C,D),B),A).
The ‘significant variant’ can be used for the creation of the tree, just like ‘separative’ and ‘conjunctive’ errors if the level above the place generating the variant is justified by error. Theoretically speaking, this means that a conjunctive variant can associate witnesses even at the higher levels of the stemma and that a variant under the same condition can have a separative value. For instance for a four-level (i.e. with five witnesses) bifurcated stemma:
[e1 ∈ A ∪ B ∪ C ∪ D ∪ E, e2 ∈ B ∪ C ∪ D ∪ E, e3 ∈ D ∪ E, e4 ∈ A, e5 ∈ B, e6 ∈ C, e7 ∈ D, e8 ∈ E, v1 ∈ A ∪ B vs v2 ∈ C∪ D � E] ⇒ ((((D,E),C),B),A).
The absence of some of the above conditions, in particular the lack of significant errors in one or more witnesses, a very frequent case in real traditions, implies a large number of possible trees and therefore a variety of texts that can be reconstructed mechanically. From a practical point of view, many expedients involving the historico-cultural aspect intervene as support, but in most cases with the consequence that the changes of the hermeneutic or epistemological paradigms correspond to changes in the trees and therefore in the texts reconstructed with their aid.
Another problem posed by the reconstructive method is the tendency to produce bifurcated trees: in this respect, the trees of the philologists and those of the biologists are surprisingly similar (Reeve, 1998; Howe et al., 2001; Howe et al., 2004; Spencer et al., 2004). The percentage of bifurcated textual trees is around 90%. Since Bédier (1928) evidenced this phenomenon, many explanations have been given (Shepard, 1930; Greg, 1931; Whitehead and Pickford, 1951; Castellani, 1957; Kleinlogel, 1968; Fourquet, 1946; Timpanaro, 1985; Reeve, 1986; Grier, 1988; Hall, 1992; Guidi and Trovato, 2004). We feel that this bifurcation of the textual trees depends on the ways in which tradition develops and that this aspect is partly connected with the analogy with the trees of life. We distinguish as follows:
C = child; F = father; i = set of; L = lost; Le = tree leaf; O = original; P = preserved; R = tree root; S = sterile (i.e. O or C never copied); T = tree; W = witness; Ω = archetype; < = descending from.
The ‘real’ T is given by iF ∪ iC, i.e. by iW, the ‘reconstructed’ T by iP. However, it should be pointed out that if an PC descends from a PF in ecdotics we are dealing with descriptus and such witness is not generally represented in the reconstructed T, which will be composed by iPC < LF. In the real T, iLe is given by iPSC ∪ iLSC, in the reconstructed T, iLe is given by iP, with the above warning.
The grade of fertility is given by the ratio between the number of W and F. The grade of fertility in the real tree of Castellani (1957), for example, is 15 F over 53 W, therefore around 3.5. With the same number of W, if the tree had a higher number of levels, fertility would increase.
Each W has from 0 to n probabilities of being copied. Whenever a W meets probability 0 there will be an SC and therefore the increase of the possibilities of extinction of the relative branch. With the same number of W, the wider horizontally is the tradition, the more likely is the extinction of the branches.
The process of decimation is not equally probable since it is much easier for the most ancient codices to disappear, either because they have more time to undergo irreparable material damage or to incur fortuitous events causing loss or decay, or because the evolution of writing can make it very difficult for them to be copied and thus less prolific. The older a W, the less prolific will it be. With the passing of time, prolificity of each single W should, as a rule, diminish, in the same way as the periods of stasis in the copy (for example when there are changes in the reproduction systems: from manuscript to print, etc.) should make sterility increase.
The likelihood of extinction of a branch increases according to the sterility of the witnesses of that branch and to the probability they have of getting lost (for example it is very high if a branch is formed by a single witness copied precociously from the original or from an ancient SC).
Even the density of W distribution on the various branches is not equally probable: the branches in which the W are from the very origins less prolific will become less and less crowded until complete extinction; while the branches in which W are from the start very prolific will be growingly populated and will have greater chance of survival.
The problem of extinction of the branches in the context of textual tradition can be compared to the problem of the “Gambler’s Ruin”, described in Raup 1991, where it is applied to the extinction of genres in biology. We can compare the number of W in a branch to the number of species in an evolutionary group and to the initial capital of a player, a chronological scale in hundreds of years to that expressed in millions of years of genres and to the temporal scale of the player. Let us imagine that for each interval of a century each W has 50 probabilities out of 100 to survive and consequently to produce new W: as occurs for species and for the player’s capital, even the number of W “will undergo a larger or smaller amount of fluctuations following a random itinerary”; it is however certain that the final extinction of the branch is an inevitable tendency and that the higher is the number of W produced the more likely it is for it to survive in the long run. In order to know the probabilities of extinction at each interval, it would be necessary to evaluate if even in the case of the textual tradition the rhythms of copy and loss of W are equivalent, in any case, however, the logic of casual itinerary would remain valid. The model of the “Gambler’s Ruin” also explains clearly the phenomenon of asymmetry of the trees (Brambilla Ageno 1975; Weitzmann, 1982, 1985, 1987; Guidi-Trovato 2004): a branch starts only from a W and is able to survive if this W is copied before extinction, if many copies are produced in the early stage then the branch life will be longer, otherwise it will die very soon.
If we consider the application of the same probabilistic model to the problem of extinction of surnames (Galton and Watson, 1875), which tries to explain the reasons for the short-lasting existence of their majority against long-term preservation of a small very diffused part (thus belonging to very extended and branched families), it is easily understood why asymmetry and very high percentage of decimation of the manuscript tradition can be indicated as causes of the phenomenon of dicotomy of the trees in ecdotics.
Other reasons can be identified if we move from real T to reconstructed T, in other words if we perform a bottom-up instead of a top-down analysis. In ecdotics the significant errors (conjunctive and separative) for the reconstruction of T are those that for their very nature are more evident and therefore are even more liable to reparatory interventions, by conjecture or by contamination. It should be added that with high prolificity the likelihood of contamination increases and therefore the ramifications that have reached us are strongly contaminated.
Correction of the errors can contribute to reduce the branches of T (Timpanaro, 1985): given a tripartite branching (A,B,C) deriving from LF which contains e1 and e2, if A corrects e2 by conjecture or by horizontal transmission from a W belonging to another branch (thus deriving from LF2) or from O, then BC will result shared by e2, against A, so that the operator will think he is dealing with a bipartite branching ((B,C),A). Likewise, given the same type of branch (A,B,C), if A introduce an error of B (e3) by horizontal transmission, then AB will result to have e3 in common, against C, thus leading once again to a bipartite T.
Horizontal transmission produces on the textual T a reduction of branching similar to the one determined in the phylogenetic T by hybridizations and horizontal transfers (transition of information from one organism to another): if, for example, a population has a mixed origin, its position in the T will be very near to its genetically closest population and the mixture will not be well represented. In short, a phylogenetic transmission with hybridations does not adapt to the model of a T (Cavalli-Sforza et al., 1994). Likewise, in the presence of contamination, textual tradition cannot be represented by a T but it will be necessary to use a reticular graph. The more reticular is the structure, the more simplified its projection onto the T.
It should be emphasized that, unlike what occurs in ecdotics, the dichotomy of the phylogenetic trees is intrinsic in the object of study and therefore the analogy recorded by the scholars is only epiphenomenally referred to the substance of things (Reeve, 1998).
3. Applications
Analysis methods inspired to information theory have been frequently used in philological surveying, with particular regard to language evolution, but also textual phylogenetics and text attribution (Benedetto et al., 2002 e 2003; Bennett et al., 2003).
The procedure we have elaborated consists in the constant recource to the digitized sources, in exploiting data-compression techniques to estimate distance matrices to be used in the successive organization in tree structures. In our applications we used the Fitch-Margoliash and the Neighbour-Joining methods of the package PhylIP (Phylogeny Inference Package) which basically construct a tree by minimizing the net disagreement between the matrix pairwise distances and the distances measured on the tree. At present the method does not exclude, but integrates traditional philological analysis. We have conducted experiments on two different traditions:
a. a modern tradition composed of 33 Chain Letters, already submitted to an analysis similar to ours by Bennett, Li, Ma (2003) and studied in depth by Vanarsdale, 1998, from whom we have drawn information relative to the dates of the witnesses (figg. 3-4);
b. an ancient tradition concerning the witnesses of the Vita Nova by Dante Alighieri (fig. 5), a work whose stemmatic structure had already been sufficiently clarified by Barbi (1907 e 1932) and Gorni (1996).
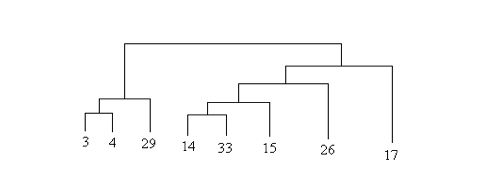
Figure 3. Partial tree, using the philological method of the 33 Chain Letters. Three variants are common to group ((3,4), 29), which has 5 variants with (14, 15, 17, 26, 33) that two other common variants identify as separate group, which is presumably in the upper part of the tree. Within this group one variant could identify a subgroup (15,17,33) and another one a group (15,33): in such case we would have ((15,33), 17), but the two variants alone do not seem to have the necessary weight to justify this hypothesis. The two variants grouping (14,15,26,33) and (14,15,33) respectively have instead more weight. Another common variant joins (14,33) (through 13, by contamination or phylogenetic intervention). Given this situation, in large part confirmed by the authomatics tree, the concordance according to the witnesses of this group with others of another group indicates possible contamination, correction or polygenetic variation, phenomena that can be hypothesized for all witnesses. This is the group resulting to be the most ancient from the date of the texts (from the end of the 60’s to the early 80’s).
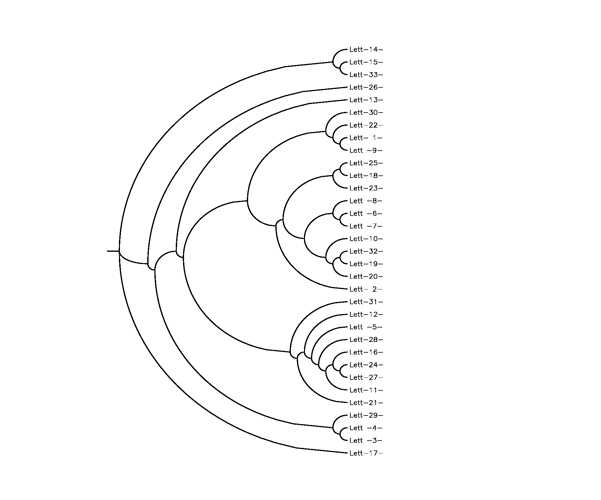
Figure 4. Phylogenetic tree of the 33 Chain Letters already analyzed by Bennett et al., (2003). The tree is obtained using the Neighbor-Joining method applied to a distance matrix whose elements are computed in terms of the relative entropy between pairs of texts. Details are reported in (Benedetto et al. 2002 and Baronchelli et al. 2005). Though the tree is unrooted we have chosen the outgroop as the letter 17 since the philological analysis gave us the indication that the letter 17 is the oldest one. Our tree is perfectly consistent with the partial one described in Fig.3 obtained with the standard philological method. The results are also consistent with the ones obtained by Bennett et al. (2003) to which we refer for a detailed description of the corpus.
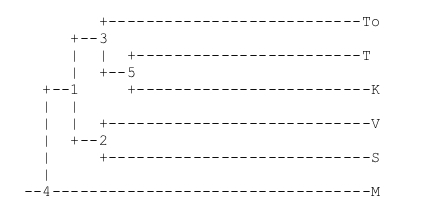
Figure 5. Phylogenetic tree of Dante’s Vita Nova. The tradition is formed by forty manuscripts, some of which are fragmentary. Among these, the manuscripts representing the entire tradition in the upper levels of the branches of Barbi’s genealogical trees and that are used by the editors for the reconstruction of the text are eight: mss. K, T, To, K2, S, V, M, O. Barbi’s tree can be summarized as follows: (((K,T),(To,K2)),((S,V),(M,O))). For this study we used the electronic edition of six of these manuscripts and the same data-compression approach used for the experiments of the chain letters (we were unable to find any digitized version of K2 and the text of O is too short to be compared with the others) edited by S. Albonico.
In both cases a substantial convergence has been evidenced between the traditional method and the compression method. The data-compression techniques and the phylogenetic methods on the whole allow to group correctly the different families of manuscripts, and therefore they represent a precious tool for ecdotic investigation: in fact they becomes essential when one is faced with a very broad tradition, the traditional analysis of which would be far too complex and long and thus unacceptable (see Robinson and O’ Hara, 1996; Baret et al., 2003; Macé et al., 2003; Mooney et al., 2003; Spencer et al., 2002; Lantin et al., 2004). The methods experimented so far have proven to be efficient and in particular rapid tools of classification, for a useful taxonomic organization of the witnesses of a text. They are in fact able to indicate the distance between two texts even if this distance is not necessarily a genealogical indication. The final aim of our preliminary work is the creation of an expert system based on the theory of information and able to identify the errors, completely independent with respect to the traditional philological methods.
References